This forum has a lot of troubleshooting articles, so I figured it would be a nice change of pace to show some of the stuff you can do with CM6.
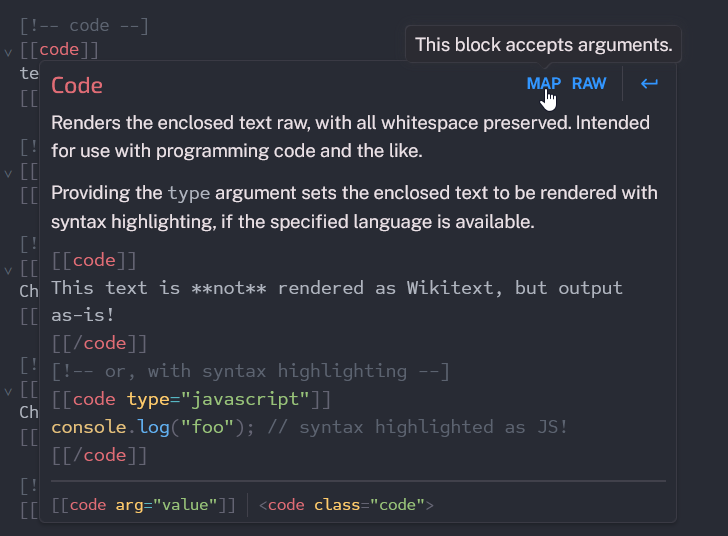
As part of a project to create a markup editor for a wiki, I elected to add what I considered an essential feature: spellchecking. There is a hack you can do where you enable spellchecking on the editor’s DOM element - that isn’t what I’m doing here. That trick will spellcheck everything - including markup. This is faster, smarter, and fancier.
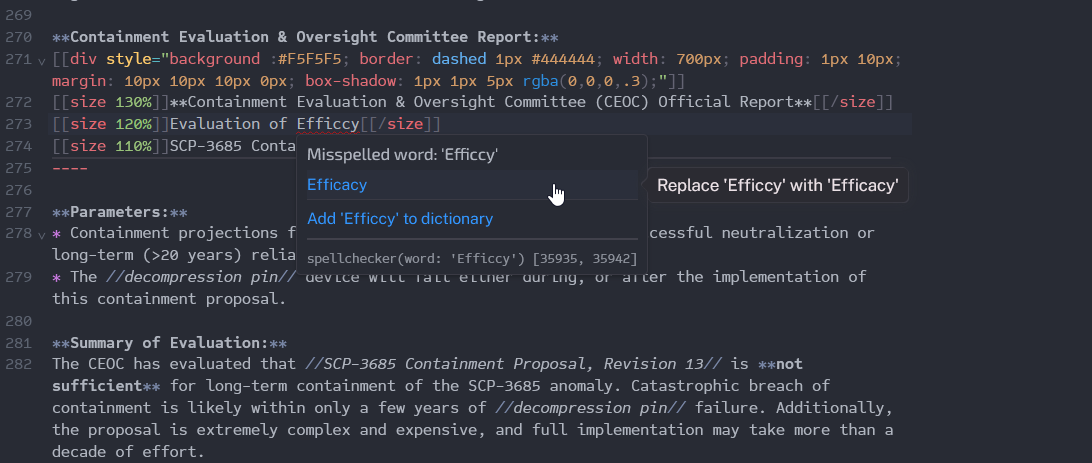
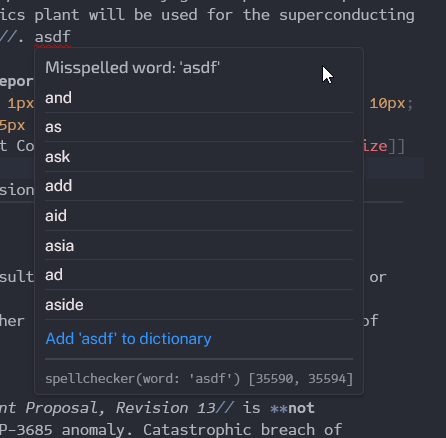
This uses the spellchecker-wasm package for the spellchecking backbone. This is all done on async worker threads, so not on the main thread. This allows it to be very fast and responsive.
One thing I wished I could’ve done is used my custom-made parser for CM6 to actually “extract” the content from the editor’s document, i.e. everything that isn’t markup. This proved impractical as both my parser and bits of CodeMirror don’t run particularly well in a worker, and I felt that it was unacceptable to run the parser in the main thread. Of course, this could be mostly avoided if I only parsed the lines visible to the user, but that will add some complexity I’m not ready for yet.
Instead, I’m doing a goofy solution where I parse the document in the worker using Prism, an intentionally crude parser for syntax highlighting in HTML content. This is because Prism is very fast and runs quite nicely in a worker. In the future, we plan to hook up the markup language’s compiler/renderer so that it has a rendering mode where it does this “extraction” operation itself. We already have that compiler hooked up for live-preview and lint warnings using WASM. Once that’s done, this will be a fairly elegant operation.
Another really frickin’ cool thing is that those tooltips aren’t the Linter tooltips - they aren’t even hand-made. Those are Svelte components. I won’t go into too much detail, but it is perfectly possible to wrap around a Svelte component in such a way that it can go into most places CodeMirror accepts a DOM element - and it works, really, really well.
Anyways, that’s all. If anyone reading this is really itching for me to release this code - I don’t think that is too feasible. It’s all open source, so you can find it if you really want to, but it’s AGPL3 licensed and also dependent on some outside state to function, like translation strings.