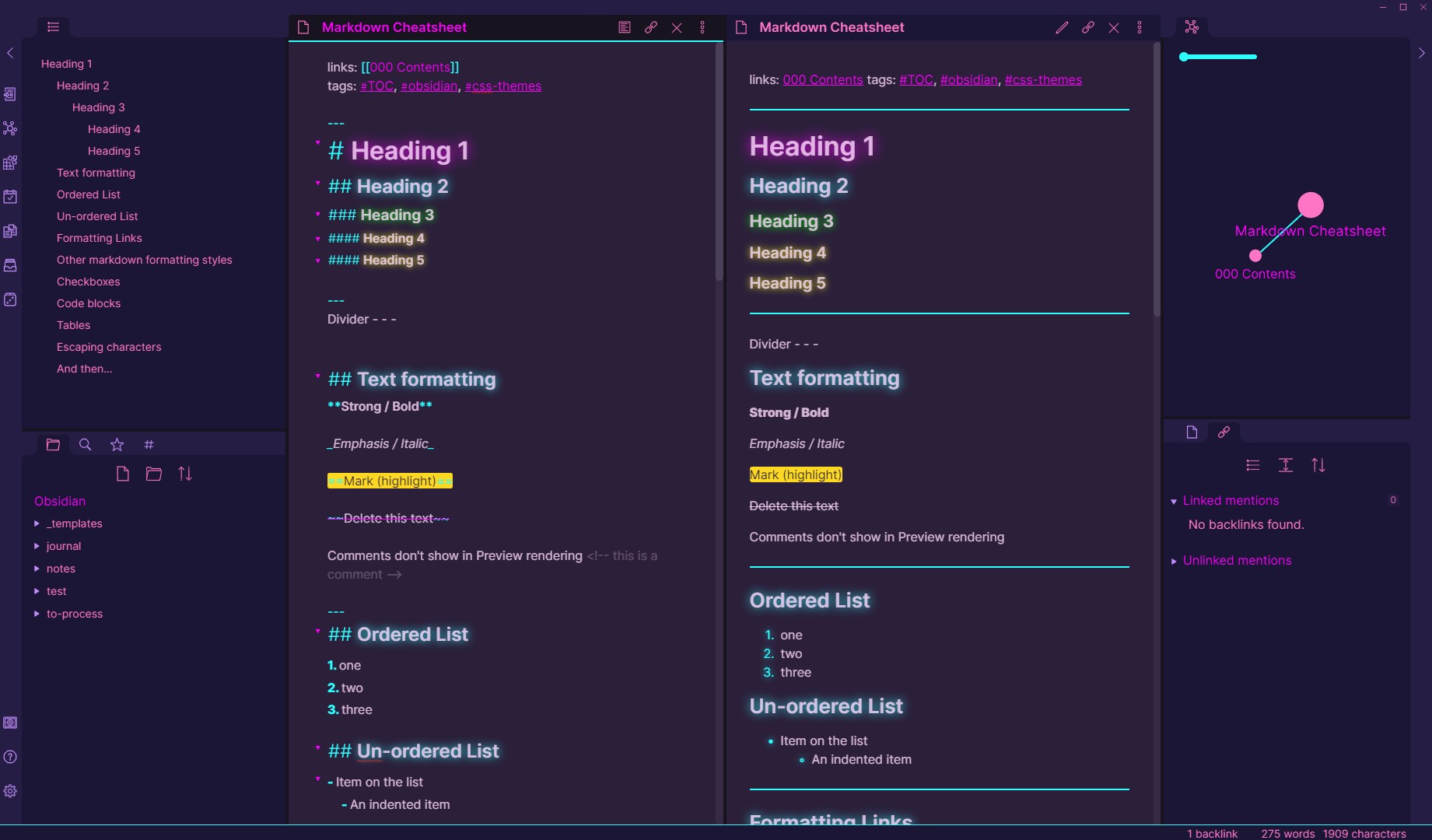
I’m noticing that there’s a collection of “CodeMirror 5 modes” which uses the StreamParser extension. Currently I wasn’t able to find any system guide documentation regarding it, other than the reference manual.
In my understanding, this acts as some kind of shim to port existing CM5 modes to CM6 with minimal changes.
My question is - is it meant to be generally usable and long-term supported? Specifically, I have a custom CM5 mode that’s a heavily modified version of HyperMD, which is a heavily modified version of GitHub-flavored markdown from CM5. Our version is also augmented with a few non-standard markdown syntaxes.
While I’d like to try and port it over to the new lezer based parser, what’s preventing me from doing so are:
I’m finding it fairly difficult to do given how difficult markdown is to parse in the first place, in that it can’t really be parsed by lezer’s LR.
I’ve attempted to read through lezer-markdown, the new CommonMark-only parser. It provides a good starting point, but there’s quite a lot of complexity in it, and after a few hours I’m still finding trouble understanding the general architecture of it. (Probably because it’s fairly undocumented).
Time constraints the bane of every programmer.
If it was possible to leverage StreamParser to quickly ship an initial version quickly, knowing the downsides of doing so, that would be great!
It seems that custom CM5 modes that rely on tokens <=> css classes will have a lot of trouble adapting to the new system. For example, we have a big stylesheet that applies styles to the various cm- tokens emitted by the CM5 mode. This would have a lot of issues with the new theme/style system, since many of the additional tokens made can’t be easily mapped to already-defined highlight Tag.
I’ve also tried looking for a system guide on how the styling architecture work. In the end, after spending a few hours with the source code, here’s what I think I’ve understood:
A language parser generates nodes as NodeType with some kind of names?
The highlighter compiles the name and tree down to highlight Tag.
The theme chooses what styles to apply for each Tag.
style-mod generates anonymous css classes for each Tag, and then associate those with the nodes as they’re generated in DOM.
Because the language parser and theme can be written by multiple independent parties, the system is designed to work with a restricted set of Tag, which is also biased towards programming languages.
What would be the intended way, if I want to assign each Node/token to have its css class to be a deterministic value? I’m guessing most likely we’ll need a custom view extension, but I haven’t found any good documentation on the architecture of that.
Yes. But it has some limitations—for example it doesn’t support nesting modes, and won’t emit proper syntax trees that, for example, the code folding can work with. If your mode descends from the old GFM mode (which is a wrapper around the old Markdown mode), then it is probably not going to be easy to port to this system.
I have plans to make the new Lezer-tree-emitting CommonMark parser extensible, but that hasn’t been a priority so far. What kind of extensions were you using?
We posted at the same time there. Regarding your second message…
Highlighting styles (which can be included in themes, but are not the same thing) basically map highlighting tags to CSS classes. To extend the highlighter vocabulary in a system, the idea would be to add some new highlighting tags, associate them with syntax nodes in your language, and define your own theme that targets them.
Those all sound like they’d fit in the parser extension system pretty well. But there’s a long list of other stuff that has more precedence right now, so it’s going to be a while until that is properly exposed and documented.
Is there a specific reason you need CSS class names? It would be possible to add support for highlighting styles that, rather then generating CSS rules with anonymous names, just assigns string names to tags, but I’m not really sure what the benefit of that would be.
On our side, it’d avoid having to port over a long stylesheet we currently use for styling CM5’s tokens. While it’s almost 1k lines of CSS, I think it’s still doable to convert to the new system so I can’t really complain.
What we’d be losing out is our 50+ community themes created via pure CSS (possibly more private themes), not all of which make modifications to cm- classes but most do in some way at least to modify the font, text size, text decoration, sizing/padding, and more crazy hacks… (You’d be surprised what people come up with, see end of post)
I’m aware some of them won’t work well with CM6, but it’s still nice to make sure the simple ones continue to work across a major upgrade.
And lastly I know this is probably not a design goal for CM6, but this post also contains a few points I’m also running into:
One drawback of this is that if a person wanted to toggle between light and dark modes by adding a class to the root of their app, they would also have to write additional javascript to toggle the theme of codemirror instead of relying on css from the app toggle.
A small, additional reason for having hardcoded / stable class-names is that it would make debugging styles a bit easier: e.g. given ͼ2, it’s hard to know looking at the class only which of the style tags were applied.
I’m definitely missing out on the benefits of using a pure-js approach to styling, but here’s some thoughts to make my case:
CSS and HTML are designed to work together and to stylize HTML semantically.
CSS is designed to be easily swapped out to “theme” semantic HTML differently.
style-mod and CM6’s styling system seems to go entirely against that by hiding away the semantics behind anonymous classes. There are good reasons for this (for example, to avoid conflicts), but it also sacrifices a lot of good things CSS/classes innately provides.
Doing things way also require any styling of CM6 be done entirely through JavaScript, which means it’s impossible to style via CSS if one only has CSS access. This may not be too common, but I’d still argue that there are valid cases where it makes sense to restrict JS access (like for security reasons as an electron app).
EDIT: I hope I don’t sound too harsh. I’m by no means trying to criticize the architecture design. I understand that our use case may not be a common one so it’s fair to assume the design is optimized for something else. Hopefully there’s some compromise that can be made without making major adjustments.
First, I’ve made a fork of StreamParser to support lookAhead because apparently the old markdown parser uses that. It’s probably not great for performance though.
I’ve also changed StreamParser to define any tag it does not recognize. This is used for lookup in the next step.
Next I’ve made a custom highlighter using the following hack:
let highlight = HighlightStyle.define();
let tagLookup = new WeakMap<Tag, string>();
// Override the CSS class lookup function to return the tag's string
highlight.match = (tag) => {
if (tagLookup.has(tag)) {
return tagLookup.get(tag);
}
let t = tags as any;
for (let key in t) {
if (t[key] === tag) {
tagLookup.set(tag, 'cm-' + key);
return 'cm-' + key;
}
}
return '';
};
And I’m happy to report that it’s working great! Probably not a great idea hacking the internals like that, but hey it works
The one thing I’m running into now is the lack of support for cm-line- classes which would previously be added to the whole line. I think it’s possible to tweak StreamParser to do so. Will report back once I get it working.
I dropped lookahead support because it complicates state reuse (you have to track how far a state looked ahead to know whether it is safe to reuse for a given change), and none of the otherwise portable modes used it (it was introduced relatively recently). Just adding the method will kind of work, but could lead to incorrect incremental re-parses.
For syntax-driven line decorations, I was thinking more in the direction of separating that into its own plugin, rather than doing it as part of syntax highlighting. No such code exists yet, though.
Yeah that’s what I suspected. I’ll dig more into this and see. I believe the markdown mode only does a single line of lookahead, so in the worst case it should still be fairly easy to support.
I see. My plan is to tweak the StreamParser to do that somehow but I don’t yet have a full understanding of how feasible it is yet… will be doing that soon. I think at worst it should still be achievable with CSS hacks.
Either way, this is more meant as throwaway code (I hope???) that will be superseded by a properly implementation once the lezer based markdown parser is extensible, and everything else is in place.
Hi @lishid, I’m writing an obsidian plugin and would like to use syntax highlighting consistent with Obsidian’s default behaviour. Could I ask whether you ended up emigrating to codemirror 6’s parsing or stuck with the modified stream parsing described above?
 the bane of every programmer.
the bane of every programmer.