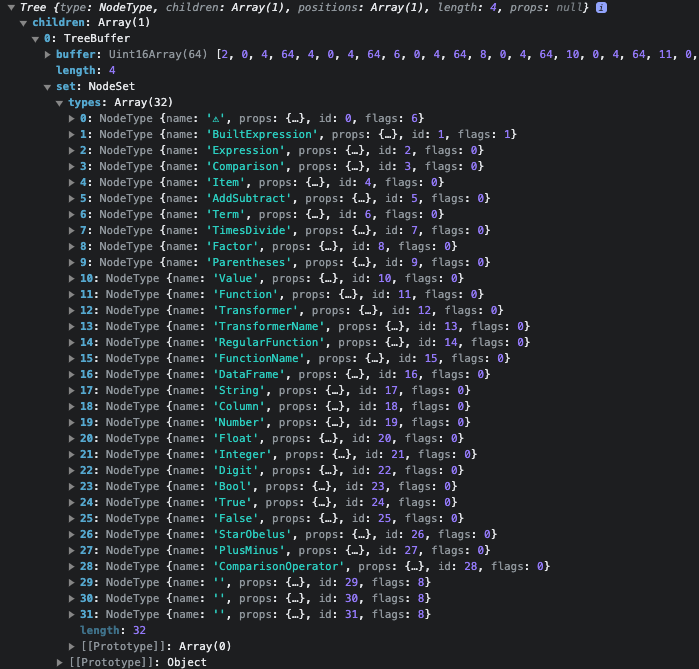
I am creating a custom language and am trying to get custom highlighting to work.
I currently have this in my language file generated by lezer-generator:
const PypelineLanguage = LRLanguage.define({
parser: parser.configure({
props: [
indentNodeProp.add({
Application: delimitedIndent({ closing: ")", align: false })
}),
foldNodeProp.add({
Application: foldInside
}),
styleTags({
ComparisonOperator: tags.operator,
PlusMinus: tags.operator,
StarObelus: tags.operator,
NotQuoteChar: tags.string,
String: tags.string,
Digit: tags.number,
TransformerName: tags.name,
FunctionName: tags.name,
True: tags.keyword,
False: tags.keyword,
})
]
}),
languageData: {
commentTokens: { line: ";" }
}
});
I have it being implemented using:
const newLang = new LanguageSupport(PypelineLanguage);
const editorState = EditorState.create({
extensions: [
keymap.of([
...defaultKeymap,
...searchKeymap,
...historyKeymap,
...lintKeymap,
// NOTE: This keymap refers to the `tab` key, NOT tabs vs spaces.
// NOTE: `indentWithTab` should be loaded after Emmet to ensure Emmet completions can take precedence
// NOTE: Warn users about ESC + Tab https://codemirror.net/examples/tab/
indentWithTab,
]),
placeholder('Enter here'),
EditorView.lineWrapping,
// autocompletion({override: [myCompletions]}),
autocompleteExtension,
newLang,
EditorView.updateListener.of((v) => {
if (v.docChanged) {
setExpressionString(v.state.doc.text[0]);
}
})
],
});
const view = new EditorView({
state: editorState,
parent: editorRef.current,
});
The editor is working fine, but the highlighting isn’t working for any values. Any help would be greatly appreciated.