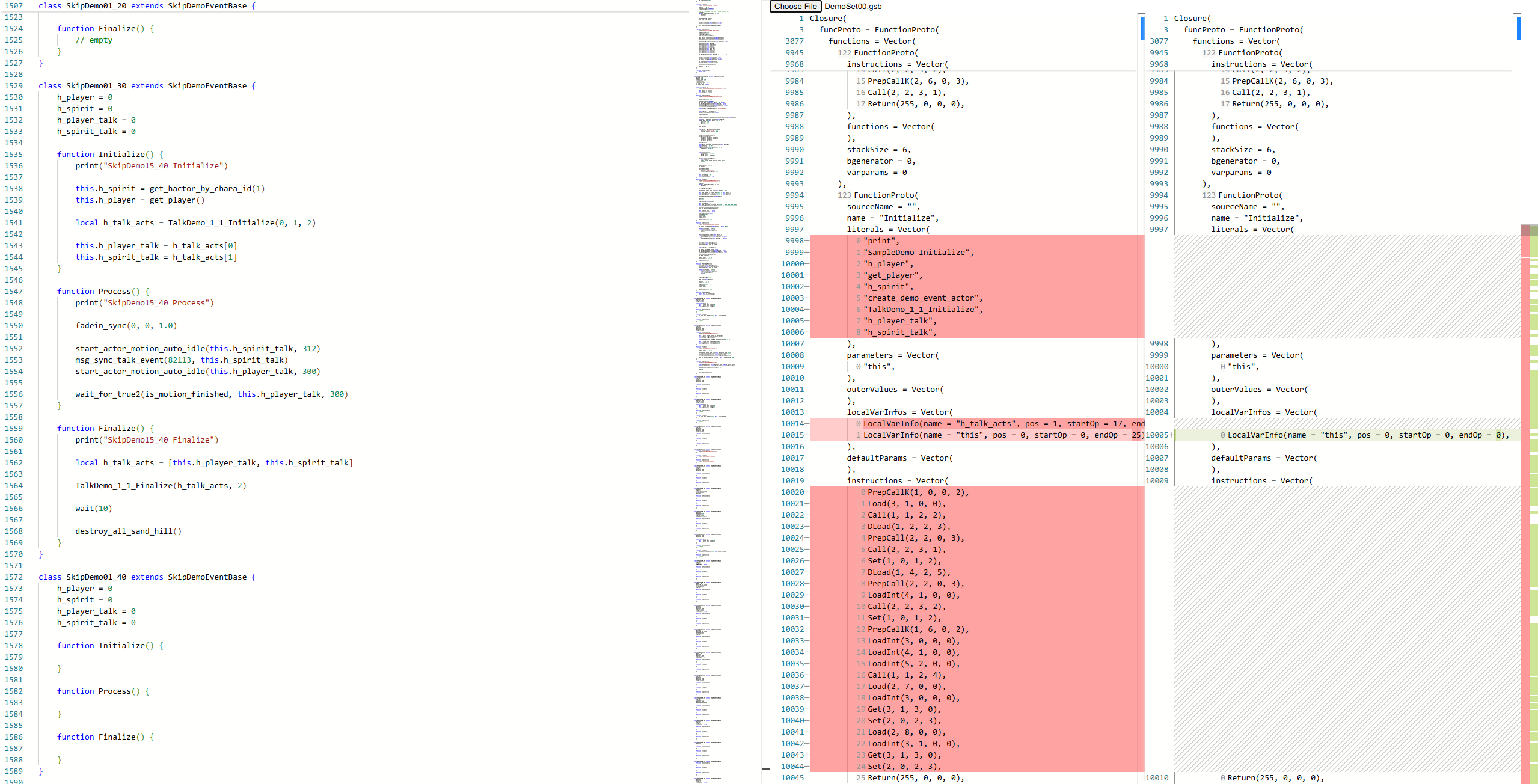
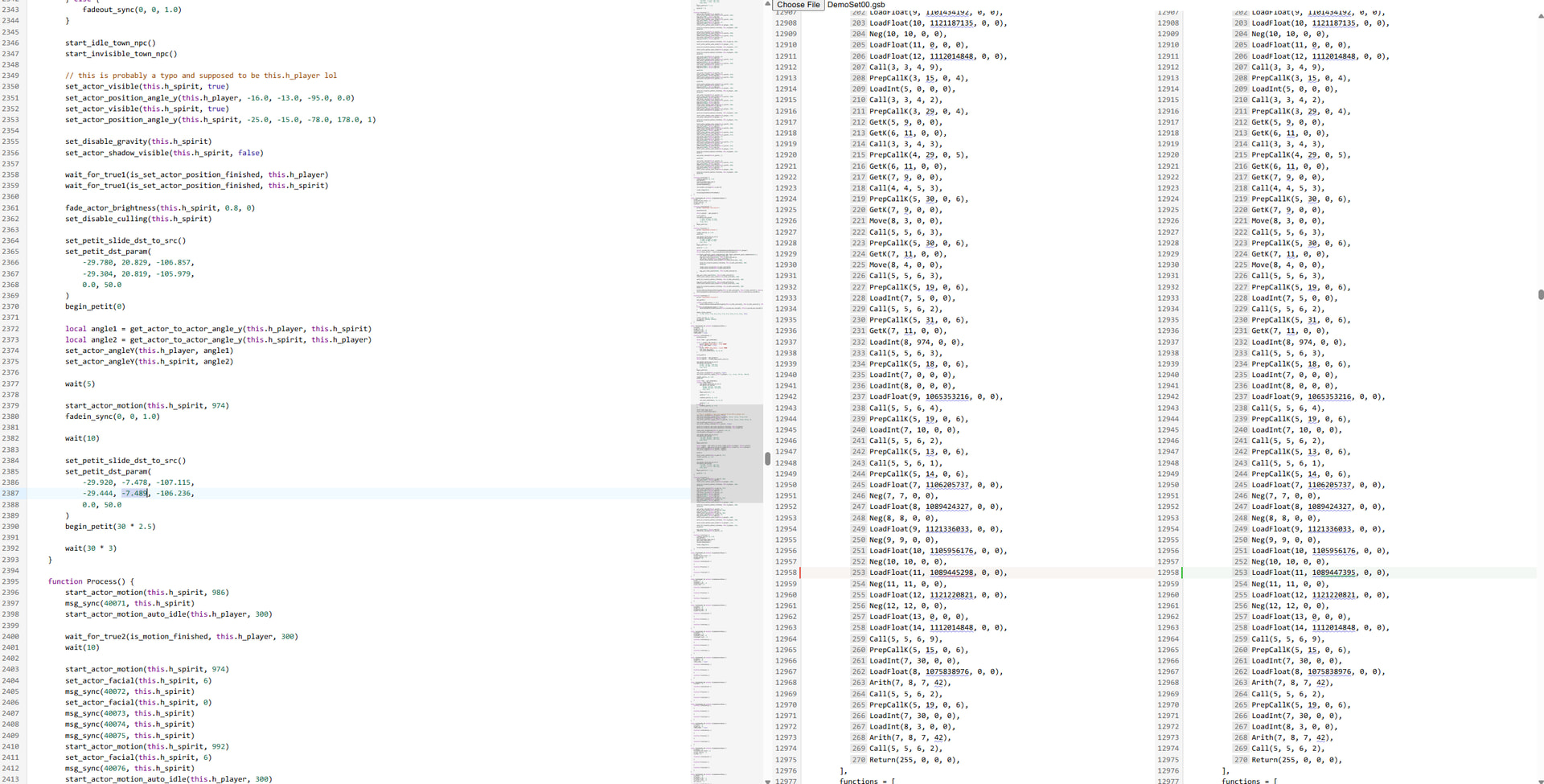
I’m moving my application Squirrel Explorer which currently uses Monaco over to CodeMirror to assist in reverse engineering Squirrel 2.2.5 bytecode files. The Monaco experience right now is this:
Beyond the nice hatch pattern for added/removed lines, and the diff minimap showing where along the files the changes are, which are just cosmetic niceities, it’s pretty important to my workflow to be able to line up instructions side-by-side. Especially to see i.e. LoadInt(1, 2, 0, 0) on line 3 be matched up with LoadInt(2, 2, 0, 0) on line 4, telling me I’m both missing an instruction and have my stack set up wrong.
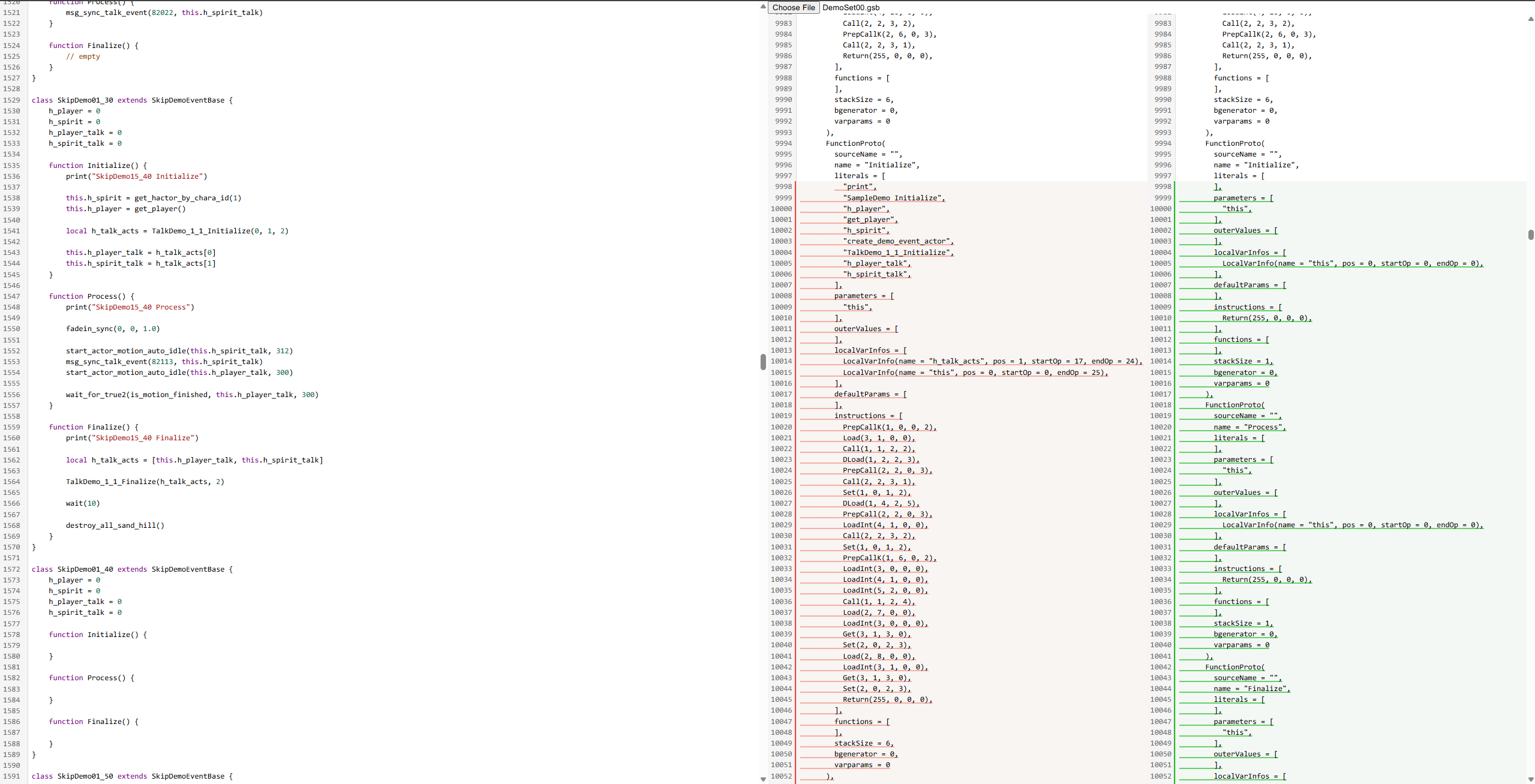
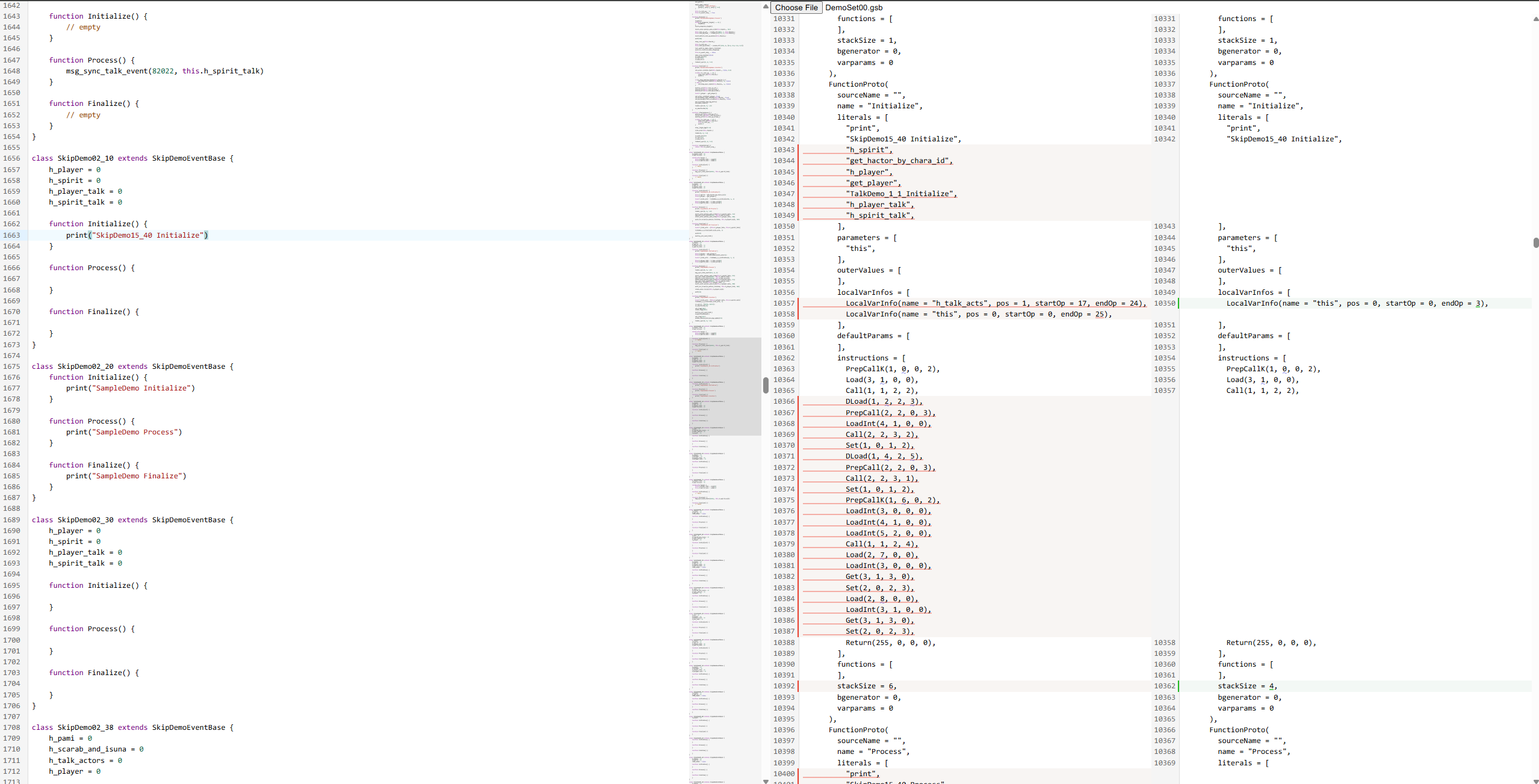
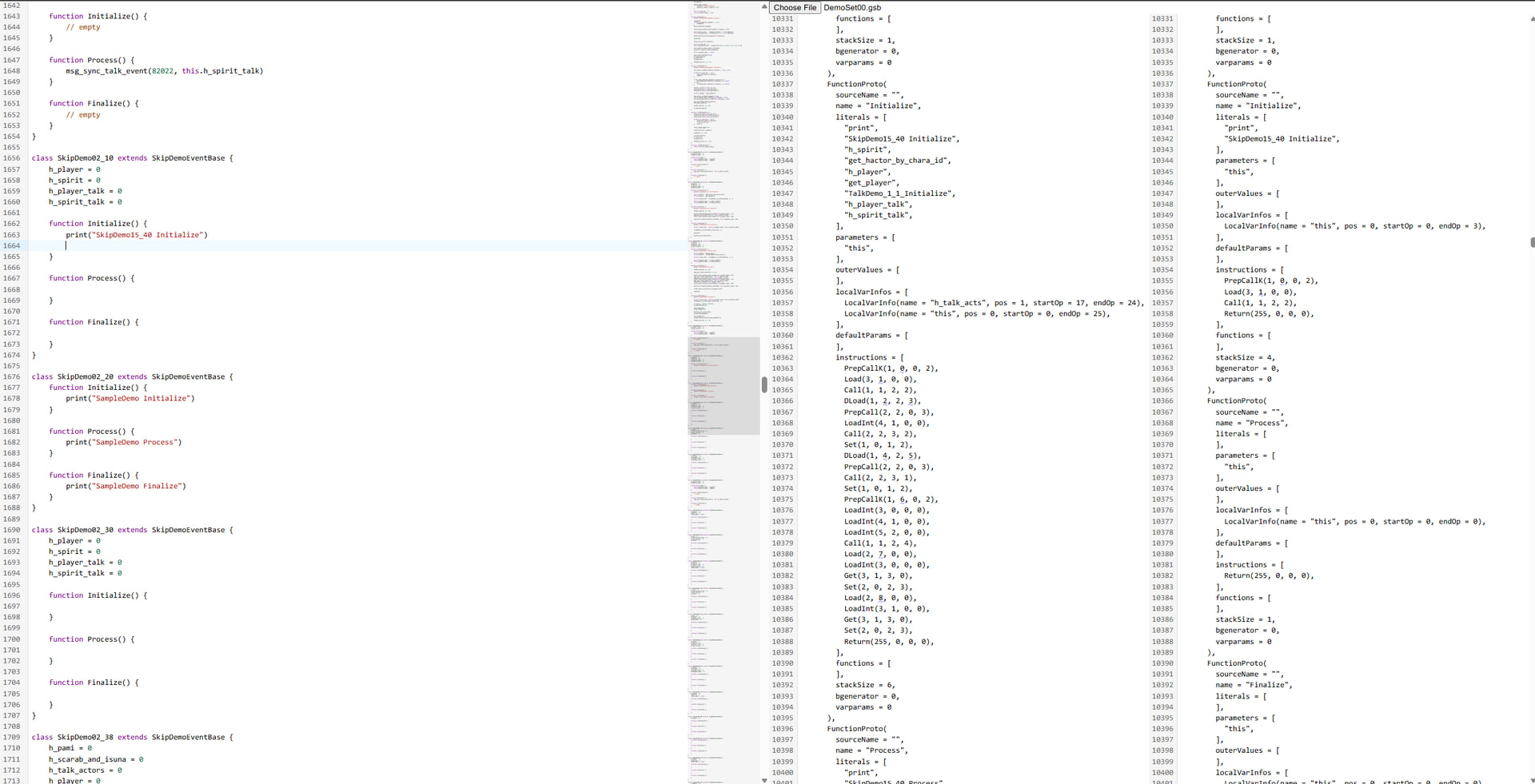
What I’m diffing is readonly, and as can be seen from the screenshot, has a lot of structure to it. However, because these outputs are upwards of dozens of thousands of lines long, I can’t use the slower diffing algorithm without the app locking up on every keystroke (Monaco resolves this issue by running the diff algorithm inside a web worker).
It would be nice if I could tell the diff algorithm something like: “for the next X lines, literals and params and outerValues and etc should line up on the [ and ], so use the slow diff algorithm on what’s between them”. Or at the very least, “use the slow algorithm for the first X lines and the fast algorithm for the rest”?
Sorry, but those aren’t things I feel would make sense to support in the diff algorithm. If it’s any help to you, I could make the algorithm pluggable, so you can bring your own.
That would actually help a lot. I already need to diff the binary representation of the data I’m outputting to the right merge view to reduce the amount of updates I’m making to it, and I could use that same logic to write the diff algorithm I want here. (The main thing I’ve never done before is matching things up within lines, but I imagine I can just grab the O(ND) algorithm already in the merge code and just run it on my small sections).
But actually, I’m not sure how to “attach” my binary representation to the editor context. I’d like to use that if possible instead of pretty printing → reparsing.
This would definitely need to happen in terms of document strings, because that’s what the library does the diffing on. Please take a look if attached patch is helpful for you.
Hmm, I’m actually really wishing I could access the editors’ states here: I already have a StateField that essentially holds the from/tos of where I pretty-printed each field to, so being able to access that would save me the trouble of re-parsing.
That being said, the only “re-parsing” I need to do here is looking for something like (\s+)(\w+) = \[, so I’ll try to get that working first.
@marijn How bad of an idea is it to call the Lezer parser inside my diff function? Bottom-up means it’ll work (as best as it can) on the partial strings, right?
That sounds like it would be very expensive, since you won’t be able to do incremental re-parses and parsing unsyntactic (incomplete) input tends to be more work.
This is definitely a “wrong” solution that I need to fix later, but running my broken/stupid algorithm for large changes & calling the smart built-in algorithm for small changes actually works with my workflow.