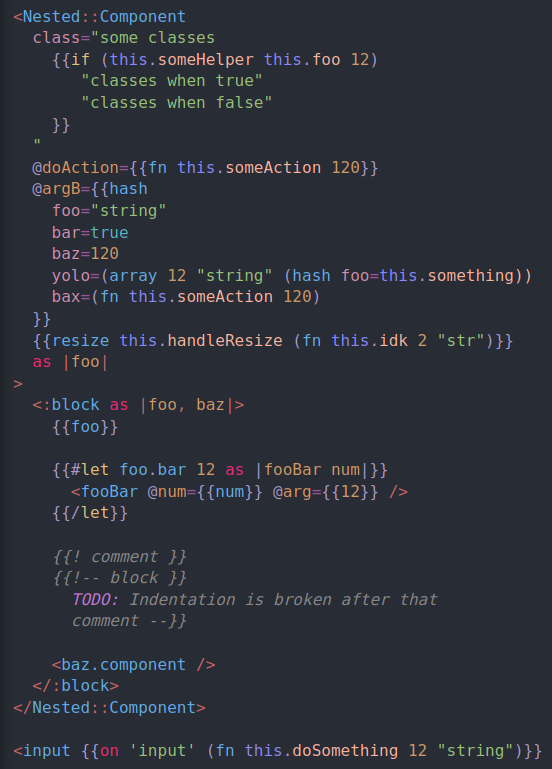
I have this error:
> lezer-generator src/glimmer.grammar -o src/parser && rollup -c
shift/reduce conflict between
Invocation -> SubExpStart SubExpression SubExpEnd · invisibles
and
Invocation -> SubExpStart SubExpression SubExpEnd
With input:
StartStache SubExpStart SubExpression SubExpEnd · invisibles …
Shared origin: Value -> · Invocation
And I’ve seen these docs: Lezer System Guide
which I think are relevant here, so I tried applying @left in @precedence for the mentioned tokens/nodes here:
@precedence {
Invocation @left,
Value @left
}
but this doesn’t change anything.
For context, here is what Invocation and Value are:
Invocation { invisibles? SubExpStart SubExpression SubExpEnd invisibles? }
Value {
boolean
| null
| undefined
| Function
| String
| Number
| Invocation
| Property
| PropertyPath
}
// related to the error:
SubExpression {
list<Value>
NamedArgs?
}
And the full thing here for more context / seeing what all the other tokens/nodes are
@detectDelim
@top Glimmer { ( Expression | BlockComment )* }
String { string }
ShortComment { StartShortComment Text* EndStache }
LongComment { StartLongComment Text* EndLongComment }
BlockComment { LongComment | ShortComment }
Expression {
StartStache SubExpression EndStache
| Block
}
Block {
StartBlock
Expression*
EndBlock
}
As { kw<"as"> "|" list<name> "|" }
StartBlock[closedBy=EndBlock] {
StartOpenBlockStache Function invisibles SubExpression? As? EndStache
}
EndBlock[openedBy=StartBlock] {
StartCloseBlockStache Function EndStache
}
Function { if | let | each | else | name }
SubExpression {
list<Value>
NamedArgs?
}
Value {
boolean
| null
| undefined
| Function
| String
| Number
| Invocation
| Property
| PropertyPath
}
Invocation { invisibles? SubExpStart SubExpression SubExpEnd invisibles? }
Pair { string "=" Value }
NamedArgs { list<Pair> }
@precedence {
Invocation @left,
Value @left
}
Argument { "@" identifier }
Property { this | Argument | identifier }
PropertyPath { Property ("." identifier)+ }
boolean {
@specialize[@name=BooleanLiteral]<identifier, "true" | "false">
}
let { kw<"let"> }
each { kw<"each"> }
if { kw<"if"> }
else { kw<"else"> }
this { kw<"this"> }
null { kw<"null"> }
undefined { kw<"undefined"> }
Number { number }
@tokens {
invisibles { @whitespace+ }
number { @digit+ | (@digit+ ("." @digit*))}
identifierChar { @asciiLetter | $[_$\u{a1}-\u{10ffff}] }
word { identifierChar (identifierChar | @digit)* }
name { word }
identifier { word }
Text { ![{] Text? | "{" (@eof | ![{] Text?) }
string {
"\"" !["]* "\"" |
"\'" ![']* "\'"
}
StartOpenBlockStache[closedBy="EndStache"] { "{{#" }
StartCloseBlockStache[closedBy="EndStache"] { "{{/" }
StartStache[closedBy="EndStache"] { "{{" }
EndStache[openedBy="StartStache | StartShortComment | StartOpenBlockStache | StartCloseBlockStache"] { "}}" }
StartShortComment[closedBy="EndStache"] { "{{!" }
StartLongComment[closedBy="EndLongComment"] { "{{!--" }
EndLongComment[openedBy="StartLongComment"] { "--}}" }
SubExpStart[closedBy="SubExpEnd"] { "(" }
SubExpEnd[openedBy="SubExpStart"] { ")" }
@precedence {
identifier,
name,
".", "=",
"|", "@",
SubExpStart, SubExpEnd,
StartLongComment, EndLongComment,
StartShortComment, StartOpenBlockStache, StartCloseBlockStache,
StartStache, EndStache,
invisibles,
string,
number,
Text
}
}
// Helper And Special Things
list<item> { item (invisibles item)* }
kw<term> { @specialize[@name={term}]<identifier, term> }
@external propSource glimmerHighlighting from './highlight'