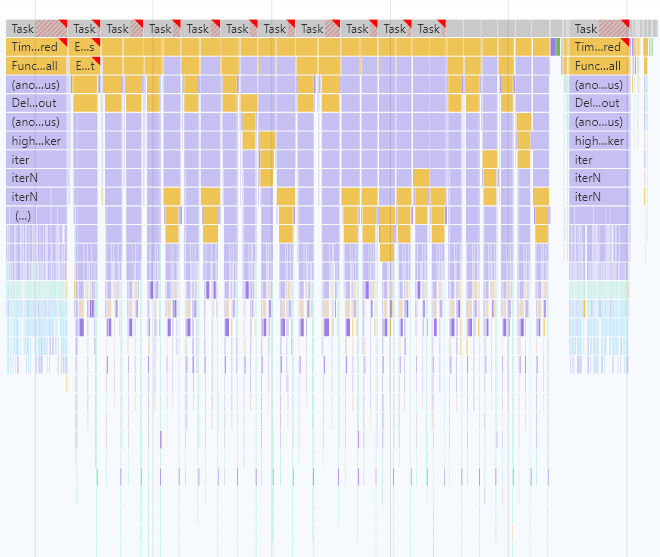
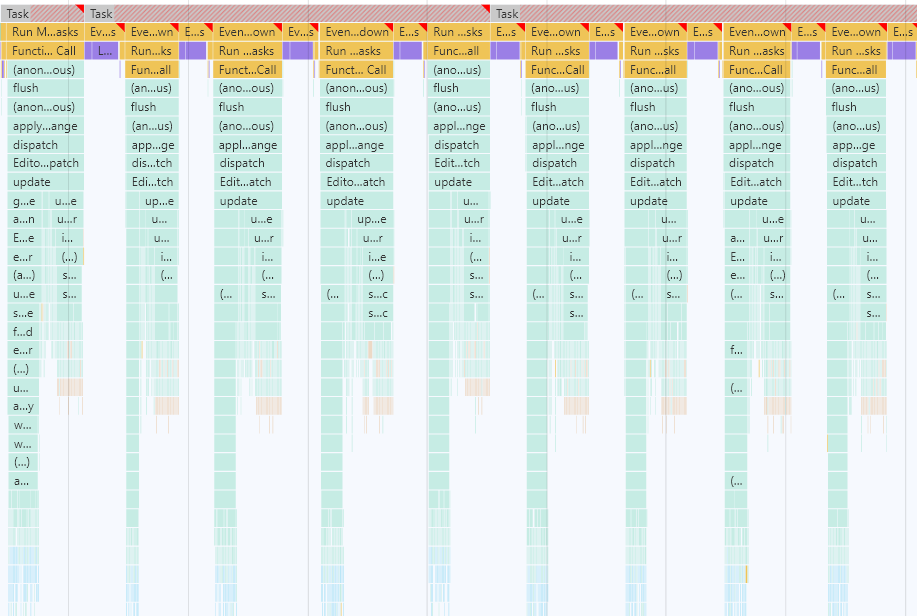
I’ve been investigating the performance differences between CodeMirror 5 and CodeMirror 6, and one major difference I’ve noticed with respect to parsing the syntax tree is that in CM5, parsing is debounced while in CM6 it is done synchronously for each docChanged transaction/update.
This has an interesting effect where typing quickly (or holding down a key for repeated character insertion) causes CM6 to use up a ton more CPU to repeatedly re-parse the syntax tree whereas in CM5 it’s only re-parsed once.
CM5:
Here we see a parse event at the beginning and one at the end.
I’ve used CPU slowdown with a mid-sized document (13kb)
The parsing step takes about 100ms in the graph (both cm5 and cm6, sharing the same parser via stream-parser)
I’m curious if this is something that can be applied for CM6, or at least, be given some sort of config to choose if and how much to defer the parsing deadline for battery savings.
CodeMirror 5 also eagerly parses the lines it redraws, but I guess that ends up not drawing attention in the profile because it is generally limited to a single line.
Various bits of state (highlighting, folding information, bracket matching, etc) in version 6 rely on the tree to be available whenever the editor is updated. As such, ‘debouncing’ parsing would incur a rather high complexity cost.
The idea is that, at least once warmed up, the incremental parser is fast enough to create a new tree in about 1 millisecond. What kind of language parser are you using in the profile?
Various bits of state (highlighting, folding information, bracket matching, etc) in version 6 rely on the tree to be available whenever the editor is updated. As such, ‘debouncing’ parsing would incur a rather high complexity cost.
Ah ok that makes sense!
The idea is that, at least once warmed up, the incremental parser is fast enough to create a new tree in about 1 millisecond. What kind of language parser are you using in the profile?
I am using a heavily modified markdown parser (modified from HyperMD) along with a modified @codemirror/stream-parser to support custom css classes, line- tokens and lookAhead. Currently, this parser is shared between our cm5 and cm6 implementations to avoid inconsistencies. We are planning on eventually re-writing this whole thing once we fully deprecate cm5, but that’s at least a year down the road.