Waiting 30 seconds should also make it move forward (if the editor is focused). This is by design—the editor tries to avoid uselessly draining your battery to parse a large document if you’re not actively interacting with it. Is this a concrete issue for you, or just something you noticed?
In my case, I’m hearing that our beta testers are seeing un-parsed documents on occasions, which is being reported as a bug with the editor. One semi-consistent repro is to load a medium sized document, make a parsing-impacting change early on in the document, then scroll down to the end. Half the time the user would see the entire page completely unparsed, and it won’t get parsed until another interaction happens.
If there’s a knob somewhere that can specify parameters of this feature that would be great! I think for me, the desired granularity would be to continuously run until the content in view is fully parsed.
We’re still using a stream-parser based mode. I haven’t gotten time yet to rewrite our CM5 mode with the new Lezer paradigm just yet, as we’re also still using CM5 on the desktop app, so we’ll have to keep supporting/updating the CM5 mode regardless.
Spent a few hours trying to reproduce the issue and testing various cases. It seems that it happens pretty rarely when attempting to repro.
I think it only happens for specific timing situations - in my test, I always type a letter early in the document which changes the parsing context, then scroll down to the bottom. Depending on the timing, most of the time, parsing catches up as I scroll (which seems to be the intended behavior). Only in rare occasions, the parsing logic seems to be completely stopped until a blur & re-focus happens. It also doesn’t seem to happen as much when scrolling using the scroll wheel, compared to scrolling by dragging the scrollbar.
It’s probably some kind of race condition, but I’m at a loss for more details. I’ve repro’d on a ~16kb and another ~80kb document.
I spent some time trying to reproduce this with the legacy JavaScript mode today (load an 80k document, make change at top, quickly scroll down with scrollbar, check highlighting, repeat), but no luck. Do you have a minimal setup that I could use to see this?
I’ve started reproducing this again on more complex documents fairly consistently.
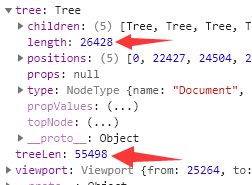
I’ve been looking at thisParseWorker checks for viewport.to > cx.treeLen. Based on the variable names I’m guessing treeLen should be equivalent to tree.length but that doesn’t seem the case. treeLen is always the size of the whole file.
Continue further down the code, it seems that treeLen is computed as stoppedAt ?? state.doc.length which makes it almost always state.doc.length unless the document is longer than 1e6 [Code]
In the meantime, I’ve changed the check to use cx.treeLen to cx.tree.length and I haven’t been able to reproduce the issue since.
Based on my limited console logging it seemed that parsing hasn’t actually finished (when this happens); it stops beyond the end of the viewport, somewhere halfway down the document.
Seems to work for me! Given this isn’t something I could reproduce reliably before, I will push this out to our beta group and see if a bigger audience can appreciate the changes.
Just a follow up on this, I’m still getting a fair amount of reports that this happens - I couldn’t reproduce the “completely stuck” state, but it seems that the parsing of documents doesn’t go beyond the current viewport enough such that scrolling gets a good experience.
In this gif, we can see that just doing normal scrolling results in a lot of just-in-time catching up where the plaintext shows up for a split second. Later on we see it stuck, and not render until I scroll up and back down again.
I’ve managed to trace this to a stream-parser bug, where Parse.advance() kept returning null.
The reason here seemed to be that the ParseWorker expects the parser to parse until some end position, but stream-parser stops at context.viewport.to, which is behind the target position. But this condition should have been caught and the context should have been notified of this skipping, except when the parser stops EXACTLY at context.viewport.to.