I’ve created an alternative Textmate-ish-kinda-sorta parser for CodeMirror 6. It’s called cm-tarnation, for no particular reason other than that I’m from Texas.
I’ll paste a bit from its readme:
An alternative parser for CodeMirror 6. Its grammar focuses on being extremely flexible while not suffering the consequence of being utterly impossible to understand. It’s inspired a bit by the Monarch and Textmate grammar formats, but pretty much entirely avoids the pitfalls of their systems.
Tarnation is not line-based. It is capable of reusing both previous and ahead data when parsing, making it fully incremental. It can restart from nearly any point in a document, and usually only barely parses the immediate region around an edit. It also doesn’t use very much memory, due to some clever usage of
ArrayBufferbased tokens.
Of course, I should say that if you can use Lezer as your language’s parser, you totally should, because it’ll be faster and likely better behaved.
So, what does it look like? You define grammars in a JSON/YAML file. Here is a complex example:
comments:
block:
open: '[!--'
close: '--]'
ignoreCase: true
repository:
ws: /[^\S\r\n]/
namela: /_?(?:@ws|@BlockEnd|$)/
BlockComment:
match: /(\[!--)([^]+?)(--\])/
tag: (...) blockComment
fold: offset(3, -3)
captures:
0: { open: BlockComment }
2: { close: BlockComment }
BlockStart:
match: /\[{2}(?![\[/])/
tag: squareBracket
closedBy: BlockEnd
BlockStartClosing:
match: /\[{2}//
tag: squareBracket
closedBy: BlockEnd
BlockEnd:
match: /(?!\]{3})\]{2}/
tag: squareBracket
openedBy: [BlockStart, BlockStartClosing]
BlockNamePrefix:
match: /[*=><](?![*=><])|f>|f</
tag: modifier
BlockNameSuffix:
match: "_"
lookbehind: '!/\s/'
tag: modifier
BlockLabel:
match: /[^\s\]]+/
tag: invalid
BlockNodeArgument:
match: /(\S+?)(\s*=\s*)(")((?:[^"]|\\")*)(")/
captures:
0: { type: BlockNodeArgumentName, tag: special(propertyName) }
1: { type: BlockNodeArgumentOperator, tag: definitionOperator }
2: { open: BlockNodeArgumentMark, tag: string }
3:
if: $0
matches: style
then: { type: CSSAttributes, nest: style-attribute }
else: { type: BlockNodeArgumentValue, tag: string }
4: { close: BlockNodeArgumentMark, tag: string }
BlockNameMap:
lookup: $var:blk_map # external variable
lookahead: /@namela/
emit: BlockName
tag: tagName
BlockNameMapElements:
# lookup is a list of strings that can be matched
lookup: $var:blk_map_el # external variable
lookahead: /@namela/
emit: BlockName
tag: tagName
# blocks
BlockNodeMap:
emit: BlockNode
indent: delimited(]])
skip: /\s+/
chain:
- BlockStart
- BlockNamePrefix?
- BlockNameMap
- BlockNameSuffix?
- BlockNodeArgument |* BlockLabel
- BlockEnd
BlockContainerMap:
emit: BlockContainer
fold: inside
begin:
type: BlockContainerMapStartNode
emit: BlockNode
indent: delimited(]])
skip: /\s+/
chain:
- BlockStart
- BlockNamePrefix?
- BlockNameMapElements
- BlockNameSuffix?
- BlockNodeArgument |* BlockLabel
- BlockEnd
end:
type: BlockContainerMapEndNode
emit: BlockNode
indent: delimited(]])
skip: /\s+/
chain:
- BlockStartClosing
- BlockNamePrefix?
- BlockNameMapElements
- BlockNameSuffix?
- BlockEnd
includes:
blocks:
- BlockNodeMap
- BlockContainerMap
global:
- BlockComment
root:
- include: blocks
Assuming that the external variables are setup correctly, you get this:
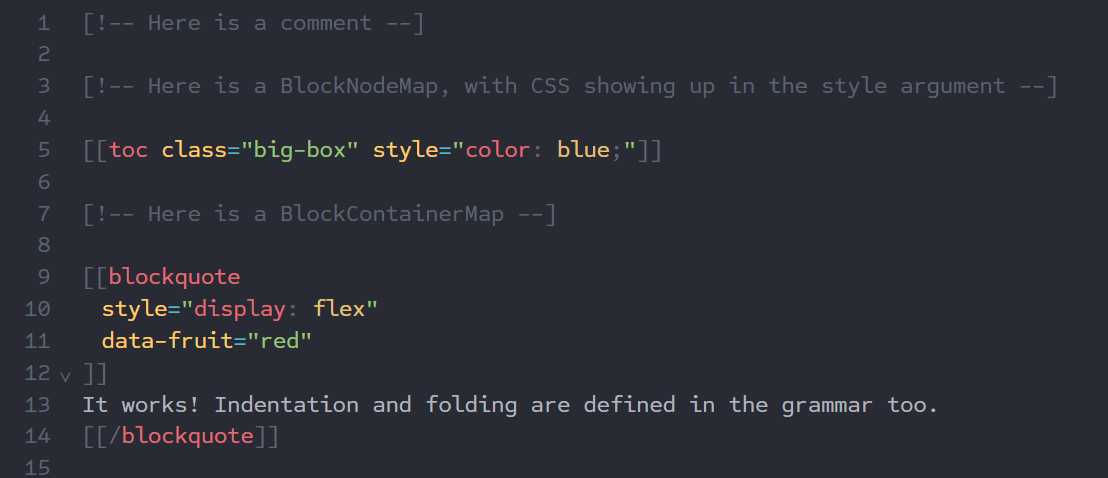
I’m scratching the surface of what you can do with this, but overexplaining it would be boring. If you want to see a ginormous grammar made with this, you can take a look at this file.
I’m very proud of this because it’s surprisingly fast and easy to use. It’s also like, my third attempt at getting something like this nice to use? I still have additional plans for it, most of which are just focused on making it behave better in certain scenarios and making defining a large grammar less tedious.