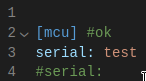
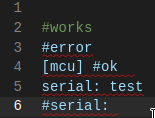
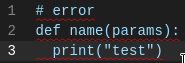
I also tried out other languages like css and there I had no problems with comments in the first line. Only my grammar and python seem to cause problems. And since both have indentation tracking in common, I commented out indentation in my grammar and also removed it in the tockenizer:
@precedence { str @cut }
@top Program { (Import | ConfigBlock)+ }
@skip { Comment newline? | AutoGenerated newline | space | blankLine }
//valueBlock<content> { indent (content newline | valueBlock<content>)+ (dedent | eof) }
sep<content, seperator> { content (seperator content)+ }
Import { "[" ImportKeyword FilePath "]" newline }
ConfigBlock {"[" BlockType Identifier? "]" newline Body? }
Body { Option+ }
Option { Parameter ":" Value | GcodeKeyword ":" Jinja2 }
Value { value (newline | eof) } // | valueBlock<value> }
Jinja2 { jinja2 (newline | eof) } // | valueBlock<jinja2> }
value { Pin | pins | VirtualPin | VirtualPin | Cords | Number | String | Boolean | Path | FilePath }
pins { sep<Pin, ","> }
VirtualPin { string ":" string }
Cords { sep<number, ","> }
Number { number }
String { string }
Path { ("/"|"~/")? !str string ("/" string)* }
FilePath { Path "." string}
//@context trackIndent from "./tokens.js"
//@external tokens indentation from "./tokens.js" { indent, dedent }
@external tokens newlines from "./tokens.js" { newline, blankLine, eof }
@tokens {
ImportKeyword{ "include" }
GcodeKeyword{ $[a-zA-Z0-9_.\-]* "gcode" }
BlockType { $[a-zA-Z0-9_]+ }
Identifier { $[a-zA-Z0-9_.\-]+ }
Parameter { $[a-zA-Z0-9_]+ }
string { ($[ a-zA-Z0-9_\-!:]+ | "//") }
jinja2 { $[ \ta-zA-Z0-9_.\-"'{}%=]+ }
number { "-"? $[0-9]+ ("." $[0-9]*)? }
Boolean { "True" | "False" }
Pin { ("^" | "~")? "!"? "P" $[A-Z] $[0-9]+ }
AutoGenerated { "#*#" ![\n\r]* }
Comment { "#" ![\n\r]* }
space { $[ \t\f]+ }
@precedence { space, jinja2, string }
@precedence { AutoGenerated, Comment }
@precedence { number, Pin, Boolean, ImportKeyword, string, "/" }
@precedence { ImportKeyword, BlockType }
@precedence { GcodeKeyword, Parameter }
}
@external propSource klipperConfigHighlighting from "./highlight"
@detectDelim
Now all of a sudden comments in the first line are skipped correctly!
Any idea how the tockenizer interferes with that?
/* ref: https://github.com/lezer-parser/python/blob/main/src/tokens.js */
import { ExternalTokenizer, ContextTracker } from '@lezer/lr'
import { newline as newlineToken, eof, blankLine } from '../parser/klipperConfigParser.terms.js' // ,indent, dedent
const newline = 10,
carriageReturn = 13,
space = 32,
tab = 9
function isLineBreak(ch) {
return ch == newline || ch == carriageReturn
}
export const newlines = new ExternalTokenizer(
(input, stack) => {
let prev
if (input.next < 0) {
input.acceptToken(eof)
} else if ((prev = input.peek(-1)) < 0 || isLineBreak(prev)) {
while (input.next == space || input.next == tab) {
input.advance()
}
if (input.next == newline || input.next == carriageReturn) input.acceptToken(blankLine, 1)
} else if (isLineBreak(input.next)) {
input.acceptToken(newlineToken, 1)
}
},
{ contextual: true }
)
/* export const indentation = new ExternalTokenizer((input, stack) => {
let cDepth = stack.context.depth
if (cDepth < 0) return
let prev = input.peek(-1),
depth
if (prev == newline || prev == carriageReturn) {
let depth = 0,
chars = 0
for (;;) {
if (input.next == space) depth++
else if (input.next == tab) depth += 8 - (depth % 8)
else break
input.advance()
chars++
}
if (depth != cDepth && input.next != newline && input.next != carriageReturn) {
if (depth < cDepth) input.acceptToken(dedent, -chars)
else input.acceptToken(indent)
}
}
})
function IndentLevel(parent, depth) {
this.parent = parent
// -1 means this is not an actual indent level but a set of brackets
this.depth = depth
this.hash = (parent ? (parent.hash + parent.hash) << 8 : 0) + depth + (depth << 4)
}
const topIndent = new IndentLevel(null, 0)
function countIndent(space) {
let depth = 0
for (let i = 0; i < space.length; i++) depth += space.charCodeAt(i) == tab ? 8 - (depth % 8) : 1
return depth
}
export const trackIndent = new ContextTracker({
start: topIndent,
reduce(context) {
return context.depth < 0 ? context.parent : context
},
shift(context, term, stack, input) {
if (term == indent) return new IndentLevel(context, countIndent(input.read(input.pos, stack.pos)))
if (term == dedent) return context.parent
return context
},
hash(context) {
return context.hash
},
}) */