I’ve been working on a complete rewrite of my cm6-monarch extension, and it differs to the point I don’t feel like it should really be called monarch anymore. Regardless, this experience has made me desire some additions to CM6 / Lezer.
Just to give an idea of my architecture / use-case here, due to it being relevant later (and maybe interesting to you), here is some key-points:
-
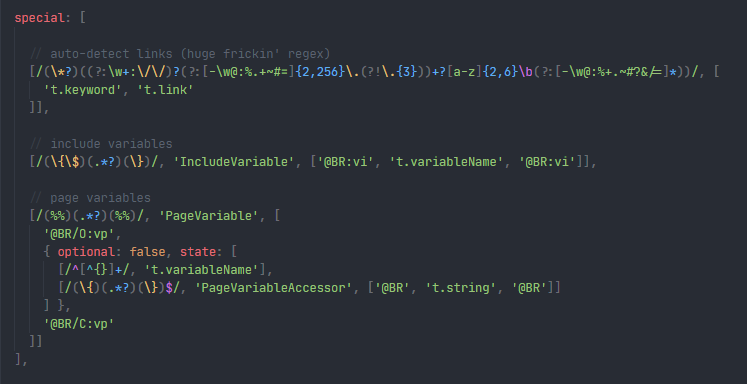
The parser runs a
tokenizer -> parserloop. The tokenizer is given a string, some positional data, and it returns a list of tokens. The tokens themselves have parser “directives” attached to them, which informs the parser about nesting. It’s similar to a Textmate grammar - except in reverse. A node is only valid when it closes, rather than eagerly matched when it opens. -
The parser outputs tokens into a flat “buffer”, like how I believe Lezer does, although in this case there is only a single “stack”, as there is only ever one route the tokenizer/parser can take. This buffer is found by association with the current syntax tree, like how the
StreamLanguagedoes it. -
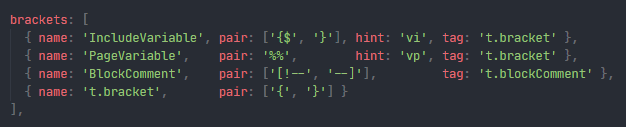
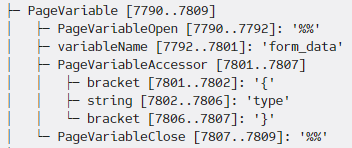
The buffer consists of two objects, many
BufferTokens, and an even distribution ofCheckpoints. -
All
BufferTokens are document-positionally relative to the lastCheckpoint- and allCheckpoints are relative to the previousCheckpoint, with the exception with the very firstCheckpoint.
What that last point means is that subtly adjusting the buffer - which is the source of data that is ultimately used in the final Tree - is really easy. You can simply move a relevant Checkpoint, and all Checkpoints infront of it move forwards/backwards with it.
Making this system has made me want two things in particular:
- A way to asynchronously parse. This can either take the form of actual plain old
Promise, or it can be some sort of function that allows a parser extension to inform CM6 that it wants the parse worker to schedule another parse some time in the future. - A way to tell
Tree.buildthat a node is to be “skipped”, or “filler”. This is so that my flat buffer doesn’t have to be carefully rebuilt if I “compress” it. What I mean by that is, is that aBufferTokencan have aTreeproperty, and if there, it will be output as a reused node. The issue arises from the fact that doing this should cause all of its children to not be output. Preserving those children nodes is useful for incremental parsing. If I can output them, and thus preserve thesizeproperty of all of the reused node’s parents, but still not have the children actually output byTree.build, that would be fantastic.
I’ll elaborate on the first one a bit more. I have a few use cases for it:
- Scheduling a reparse of a nested language region due to the language async load finishing.
- Doing some really expensive action - say, using a bunch of
requestIdleCallbackin order to compress a tree and get a bunch of reusable nodes without having to do it during a time sensitive parse. - And of course, just plain ol’ async parsing. Maybe it’s something that works with a web worker, or maybe its a “fine” parse vs a course sync parse, like a detailed semantic tokens pass.
I know this introduces issues with how parsing currently works. It’s quite handy that parsing is synchronous for everything interfacing with CM6. I think this should be preserved! A synchronous parse should always be supported in some sense - if a bit of code calls SyntaxTree, the parser should have some sort of output when it’s forced to finish synchronously.
I think that latter situation could be helped with an “urgent” property in parse context object. Or maybe simply what the timeout is for the parser, e.g. 25 milliseconds.
Oh, and on the second request - I did try making a custom BufferCursor class for it, but I just disliked how messy the position index reporting got. Instead, I just process the whole buffer into a valid Tree.build node list beforehand.
Finally, man CM6 is fast, regardless of what I throw at it. What sorcery is this!?