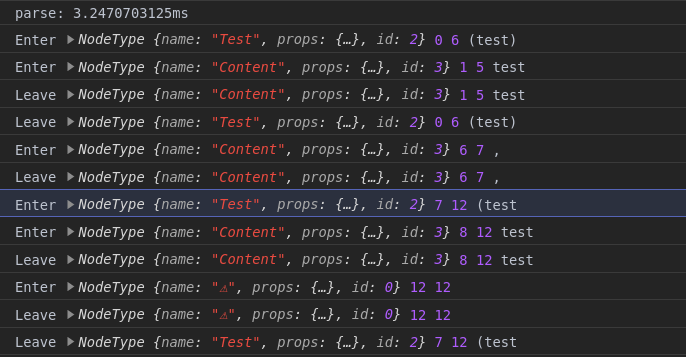
Tokens are always ‘atomic’, even if they use capitalized sub-rules. So in the second grammar, Content doesn’t even show up as a term in the generated parser, it’s conceptually inlined into Test.
That’s why there is an error node after the Content node—the error correction broke off the Test rule early because it couldn’t produce a valid parse. Pass {strict: true} if you want the parser to throw an error in cases like that.